
|

|
|
|
|
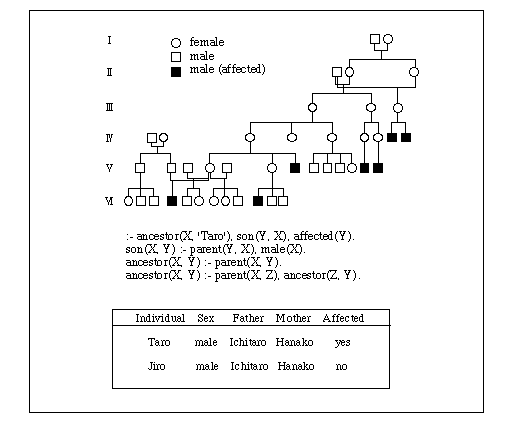
病気の遺伝子のゲノム上の位置を知るために行われるリンケージ解析では、上図に示したような家系分析のデータが出発点である。親子関係をたどって、祖先に発病した人がいるかを調べるといった検索を関係データベースの SQL だけで実現することはむずかしい。一方、親子関係を繰り返し使うような再帰的な質問は論理型言語により素直に表現できる。そこで、まず述語論理(predicate logic)と呼ばれる分野を簡単に説明しておこう。
述語(predicate)とは変数に具体的な値を与えて真偽が定まる言明のことで、あらかじめ真偽が定まっている言明である命題(proposition)と対比される。例えばXとYを変数として、「X は Y の親である」という言明は述語である。述語は1つの論理式であるが、さらに選言(または)、連言(かつ)、否定(~でない)、含意(~ならば)、全称(すべての)、存在(~が存在する)などの論理演算を含むものも論理式である。論理式を使った述語論理の体系には多くの種類があるが、その中で1階述語論理は計算機との関係が深い。1階述語論理の論理式の中で
P ← Q1, Q2, ..., Qn ← Q1, Q2, ..., Qn P ←の3種類からなるホーン節(Horn clause)に基づき、コワルスキー(Robert A. Kowalski)らは Prolog 言語を開発し1972年に実用化された。上記のホーン節の1番目のものはルール節と呼ばれ「Q1 かつ Q2 かつ ... かつ Qn ならば P である」というルールを表現している。3番目のものは単位節と呼ばれ、単位節の中で変数を含まないものをファクトと呼ぶ。2番目のものはゴール節と呼ばれ、実はこれが質問に対応している。
図の例では「X は Y の親である」という単位節を parent (X, Y) で、「X は Y の祖先である」という単位節を ancestor (X, Y) で表現してある。当然ながら、親も祖先に含まれるので、
ancestor (X,Y) ← parent (X, Y)が成り立ち、また祖先の親はまた祖先であるので
ancestor (X,Y) ← parent (X, Z), ancestor (Z,Y)が成り立つ。さらに「Taro の親は誰であるか」という質問は
← parent (X, 'Taro')と書くことができる。図ではこれらが Prolog 的に書いてあり、関係データベース的にテーブルにまとめてある個人情報と一緒にして、祖先に発病者があるかどうかを検索することができるのである。このように関係データベースと述語論理による演繹機能を組み合わせたものを、演繹データベース(deductive database)という。
一方、関係データベースは述語論理の立場から眺めるとファクトを集めたものと見なすことができる。例えば、図のテーブルの部分は person (Individual, Sex, Father, Mother, Affected) という述語使って
person ('Taro', 'male', 'Ichitaro', 'Hanako', 'yes')と記述することができる。実際、関係データベースは関係代数のかわりに関係論理(relational calculus)に基づく演算系として定義することができ、この意味で演繹データベースは関係データベースを1階述語論理に基づき自然な形で拡張したものになっているのである。当初、Prolog などの論理型言語を用いた論理プログラミングは推論や探索などの人工知能の諸問題に適応されていたが、演繹データベースによりデータベースの問題との間に自然な接点が生まれたことは大変興味深い。
person ('Jiro', 'male', 'Ichitaro', 'Hanako', 'no')
...