
|

|
|
|
|
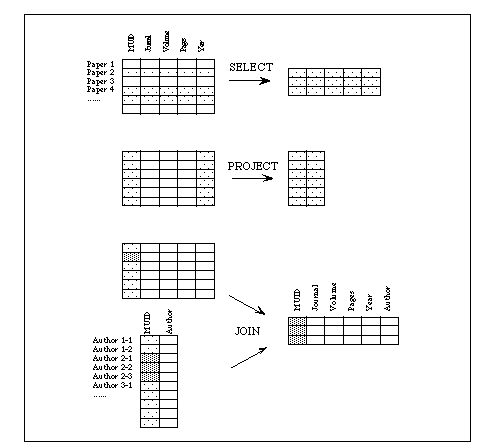
関係データベースは直観的にも分かりやすいデータベースで、上図に示したようにデータをテーブルの形に蓄積したデータベースである。テーブルの1行が1つのレコードに対応し、列(カラム)がレコードの属性に対応している。ここでは文献データを関係データベース化した例で、文献番号 MUID (Medline Unique ID)、雑誌名、巻、頁、発行年を1つのレコードの単位としてデータが蓄積されている。ここで、例えば特定の雑誌に発行された文献だけを探す操作は、テーブルの中の特定の行を抜き出して新しいテーブルを作る操作に対応し、これを選択(selection)という。一方、特定の属性だけに着目し、列を抜き出して新しいテーブルを作る操作は射影(projection)と呼ばれる。図の例ではさらに著者に関する別のテーブルがあり、例えば特定の雑誌に特定の著者が発表した文献を探すには、2つのテーブルを同時に検索する必要がある。これを可能にするのが結合(join)と呼ばれる操作で、指定された共通の属性の値が同じである行が1つにまとめられる。ここでは文献番号が同じであるレコードが結合されている。
このように眺めてくると、関係データベースにおける検索などの操作はテーブルに関する演算に相当し、これは集合演算を拡張したようなものになっている。実際、関係データベースには関係代数(relational algebra)と呼ばれる数学的基礎があり、実用的なシステムを作る上での強みになっている。一方、関係データベースの弱点は実世界のデータを表現する力に乏しいことであろう。平坦な関係だけでデータを表現しようとするとどうしても無理があり、多数のテーブルを定義する必要が生じて効率の悪い結合演算の回数が増えてしまう。図の著者名のテーブルではそれぞれの文献での複数の著者が同列のレコードとして扱われているが、直観的には文献でまず分けて、その下に個々の著者を並べる階層的な構成の方がふさわしい。関係モデルにこのような入れ子関係を許して拡張した非正規関係モデルというものも提唱されたが、あまり実用化はされていない。
一般にデータベースシステムを利用するための言語をデータベース言語という。関係データベースシステムの場合には関係代数を言語的に表現したものがいくつか知られているが、とくに SQL (Structured Query Language) と呼ばれる言語が標準的である。SQL での検索は
Select 属性名の並び From 関係名(テーブル名)の並び Where 条件
といった形で記述され、例えば
Select MUID From TABLE1 Where JOURNAL = "Nature"といった英語の文章のような感じで書くことができる。なお、属性名の並びを指定することにより射影の演算が、複数のテーブルが指定されると自動的に結合の演算が実行されることに注意していただきたい。