
|

|
|
|
|
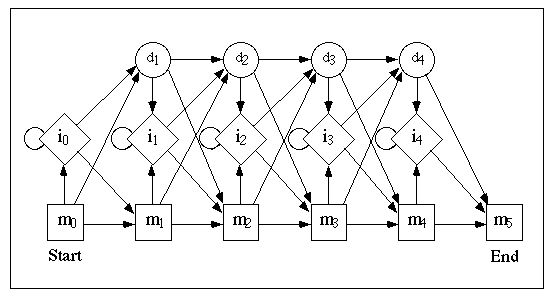
丂俛俴俙俽俿傾儖僑儕僘儉偺強偱弎傋偨桳尷僆乕僩儅僩儞傪奼挘偟丄忬懺慗堏偑妋棪揑偵婲偙傞偲偟偨僆乕僩儅僩儞傪妋棪僆乕僩儅僩儞乮probabilistic automaton乯偲偄偆丅偦偺堦庬偲偟偰丄壒惡擣幆偱巊傢傟偰偒偨塀傟儅儖僐僼儌僨儖乮HMM: hidden Markov model乯偼丄儅儖僐僼楢嵔乮Markov chain乯偺奺忬懺偵婰崋偺弌椡妋棪傪梌偊偨傕偺偱丄攝楍偺僷僞乕儞擣幆偵傕旕忢偵桳岠偱偁傞丅忋恾偵侾偮偺儌僨儖偑彂偐傟偰偄傞丅偙偙偱丄m0 偼弶婜忬懺丄m5 偼嵟廔忬懺偱丄m1 偐傜 m5 傑偱巐妏偱帵偟偨忬懺偼攝楍拞傑偨偼攝楍傾儔僀儊儞僩拞偺埵抲傪帵偟丄偦傟偧傟偵墫婎攝楍偱偁傟偽係庬偺丄傾儈僲巁攝楍偱偁傟偽俀侽庬偺婰崋偺弌椡妋棪偑懚嵼偡傞丅攝楍偵偼寚幐丒憓擖偑婲偙傞偙偲傪峫椂偟丄恾偱偼庡忬懺偱偁傞 mk 埲奜偵丄婰崋偺寚幐忬懺 dk 偲憓擖忬懺 ik 偑彂偐傟偰偄傞丅憓擖忬懺偵偼傗偼傝婰崋偺弌椡妋棪偑懚嵼偡傞偑丄寚幐忬懺偼婰崋偑弌椡偝傟側偄僟儈乕忬懺偱偁傞丅偙偺傛偆偵丄墫婎攝楍傗傾儈僲巁攝楍偼儅儖僐僼楢嵔偵傛偭偰婰崋楍偑惗惉偝傟偰偄傞偲壖掕偡傞偑丄儅儖僐僼楢嵔偺忬懺慗堏偺條巕偼捈愙偵偼尒偊側偄乮儌僨儖偺忬懺慗堏恾偵偼婰崋偺弌椡偑彂偐傟偰偄側偄乯偺偱丄乽塀傟乿儅儖僐僼儌僨儖偲偄偆偺偱偁傞丅
丂恾偺傛偆側摿掕偺儌僨儖偼懡悢偺攝楍僷僞乕儞傪惗惉偡傞丅惗惉偝傟偨屄乆偺攝楍僷僞乕儞偵偼忬懺慗堏妋棪偲婰崋弌椡妋棪偐傜寁嶼偝傟傞妋棪偑晅悘偟偰偄傞丅堦斒偵摨偠攝楍偑暋悢偺宱楬偐傜惗惉偝傟摼傞偺偱丄偦傟傜傪懌偟崌傢偣偨傕偺偑侾偮偺攝楍偵懳偡傞妋棪偱偁傞丅偄傑丄塀傟儅儖僐僼儌僨儖傪婡擻晹埵梊應偵揔梡偡傞偙偲傪峫偊傞偲丄婡擻晹埵偺攝楍僌儖乕僾偵懳偟偰偩偗崅偄妋棪傪梌偊傞傛偆側儌僨儖傪尒偮偗傞偙偲偑栤戣偲側傞丅偙傟偼僩儗乕僯儞僌僨乕僞僙僢僩偵妛廗傾儖僑儕僘儉傪揔梡偟丄塀傟儅儖僐僼儌僨儖偺僷儔儊僞偱偁傞忬懺慗堏妋棪偲婰崋弌椡妋棪傪嵟揔壔偡傞偙偲偵傛傝丄傑偨応崌偵傛偭偰偼儌僨儖偺挿偝傕嵟揔壔偡傞偙偲偵傛傝夝偔偙偲偑偱偒傞丅
丂偄傑丄僩儗乕僯儞僌偺攝楍僨乕僞 s(1), s(2), ..., s(n) 偑梌偊傜傟偨偲偒偵丄偙傟偑 儌僨儖偵偳偺掱搙揔崌偡傞偐偼丄偦傟偧傟偺攝楍偑摨帪偵婲偙傞妋棪偱偁傞偺偱
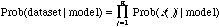
偱昡壙偡傞丅偙傟偼丄嵟栟乮ML: maximum likelihood乯朄偺峫偊曽偱偁傞丅傕偆侾偮偺峫偊曽偱偼丄儀僀僘偺朄懃偵傛傝嵟戝帠屻妋棪乮MAP: maximum a posteriori乯

傪梡偄偰昡壙偡傞丅偙偙偱丄Prob(model) 偼帠慜妋棪丄Prob(dataset) 偼婯奿壔偺偨傔偺掕悢偱偁傞丅MAP 偼嵟彫婰弎挿乮MDL: minimum description length乯偵傕捠偠傞峫偊曽偱丄儌僨儖偺暋嶨偝乮妋棪偲偟偰昞尰偝傟偰偄傞乯傪壛枴偟偰僩儗乕僯儞僌僨乕僞傊偺揔崌惈傪寛傔傞丅偮傑傝丄偁傑傝偵傕暋嶨側儌僨儖偱僩儗乕僯儞僌僨乕僞偵傄偭偨傝崌傢偣傞傛傝傕丄扨弮側儌僨儖偱僩儗乕僯儞僌僨乕僞偑偦偙偦偙崌偊偽傛偄偲偄偆峫偊偱偁傞丅
丂塀傟儅儖僐僼儌僨儖偺妛廗傾儖僑儕僘儉偼師偺傛偆側拃師揑曽朄偱偁傞丅傑偢丄揔摉側弶婜儌僨儖傪慖傇丅僩儗乕僯儞僌僨乕僞僙僢僩偺奺攝楍偵偮偄偰壜擻側宱楬傪偡傋偰挷傋丄幚嵺偵婲偙傞忬懺慗堏偺昿搙偲婰崋弌椡偺昿搙傪傕偲偵丄ML 傑偨偼 MAP 偺堄枴偱慗堏妋棪偲弌椡妋棪傪峏怴偟偰師偺儌僨儖偲偡傞丅偙偺庤懕偒傪峏怴偑偛偔傢偢偐偵側傞傑偱孞傝曉偡丅偲偙傠偱丄塀傟儅儖僐僼儌僨儖偼妋棪揑側堄枴偱嶌傜傟偨僾儘僼傽僀儖偲旕忢偵嬤偄娭學偵偁傞丅塀傟儅儖僐僼儌僨儖偺曽偑寚幐偲憓擖傪柧妋偵掕媊偟偰偄傞偨傔懡彮堦斒揑偱偁傞偑丄偦偺婰崋弌椡妋棪偼傑偝偵僾儘僼傽僀儖偱偁傞丅塀傟儅儖僐僼儌僨儖偺妛廗傾儖僑儕僘儉偼丄婜懸嵟戝壔乮EM: expectation maximization乯偲屇偽傟傞曽朄偺堦庬偱偁傝丄幚嵺偙偺峫偊曽偱僾儘僼傽僀儖傪拃師揑偵峏怴偟偰偄偔曽朄偑採埬偝傟偰偄傞丅偲偔偵丄僊僢僽僗僒儞僾儕儞僌乮Gibbs sampling乯偲屇偽傟傞曽朄偱偼丄儊僩儘億儕僗儌儞僥僇儖儘傗僔儈儏儗乕僥僢僪傾僯乕儕儞僌偵傕捠偠傞擬暯峵暘晍傊偺娚榓偺峫偊曽傪庢傝擖傟偨埖偄偑偝傟偰偄傞丅