|

|
|
|
|
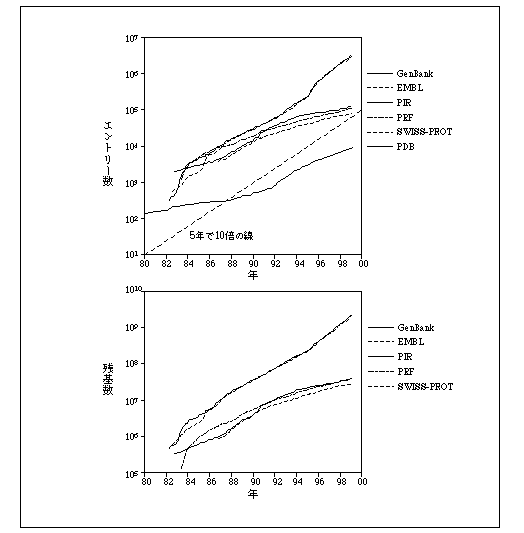
丂幚尡媄弍偺恑曕偲忣曬岞奐偺棳傟偵傛傝丄壓恾偵帵偟偨傛偆偵侾俋俋侽擭戙偵擖偭偰俹俢俛偺僨乕僞検偑媫憹偡傞傛偆偵側傝丄攝楍僨乕僞儀乕僗偵嬤偄怢傃棪偵側偭偰偄傞丅偟偐偟側偑傜偙偺恾偑帵嵈偡傞傛偆偵丄棫懱峔憿偑夝柧偝傟偨僞儞僷僋幙偼堦師峔憿偑夝柧偝傟偨傕偺偺俆亾掱搙偵偟偐夁偓側偄丅傕偪傠傫偙偙偱偼摨偠攝楍傗椶帡側攝楍丄摨偠棫懱峔憿傗椶帡側棫懱峔憿偑懡悢廳暋偟偰悢偊傜傟偰偄傞偺偱丄儐僯乕僋側僼傽儈儕乕偁傞偄偼僗乕僷乕僼傽儈儕乕偺悢偲偟偰偄偔偮偢偮偁傞偐娙扨偵偼暘偐傜側偄丅偟偐偟偄偢傟偵偣傛丄夝柧偝傟偨攝楍偲棫懱峔憿偺斾偲偟偰偼戝嵎側偄傕偺偲巚傢傟傞丅
丂俹俢俛偼挊幰偐傜憲傜傟偨僨乕僞傪偦偺傑傑嵞攝晍偡傞偨傔偺儗億僕僩儕乕揑側惈奿偑嫮偄偙偲丄倃慄寢徎夝愅傗俶俵俼偵傛傞棫懱峔憿僨乕僞偼攝楍僨乕僞傛傝傕暋嶨偱偁傞偙偲偐傜丄俹俢俛偺僨乕僞傪偝傜偵夝愅偟曇惉偟側偍偟偨擇師揑側僨乕僞儀乕僗偑偄偔偮偐懚嵼偡傞丅偦偺拞偱傕偲偔偵桳梡側偺偼棫懱峔憿偺椶帡惈偐傜僼僅乕儖僪偺暘椶傪峴偭偨僨乕僞儀乕僗偱偁傞丅椺偊偽 SCOP (Structural Classification Of Proteins) 偲屇偽傟傞僨乕僞儀乕僗偱偼棫懱峔憿傪兛宆丄兝宆丄兛乛兝宆丄兛亄兝宆側偳偵暘偗丄偦傟偧傟偱峔憿偺椶帡惈偐傜僼僅乕儖僪丄僗乕僷乕僼傽儈儕乕丄僼傽儈儕乕偲偄偆奒憌暘椶傪峴偭偰偄傞丅偙傟偼俹俬俼僨乕僞儀乕僗偺僗乕僷乕僼傽儈儕乕丄僼傽儈儕乕奒憌暘椶偵丄僼僅乕儖僪傪偮偗壛偊偨傕偺丄偡側傢偪攝楍偺椶帡惈偼側偔偰傕棫懱峔憿偺椶帡惈偼尒傜傟傞応崌傪峫椂偟偨偙偲偵憡摉偡傞丅