
|

|
|
|
|
データベースとはデータの集まりであるが、検索その他の使用目的があること、多くの利用者に共同利用されること、データが項目ごとに組織化されていることなどが、概念として含まれている。データベース管理システムによって取り扱われることが前提となっているので、計算機処理が可能なようにデータが定義されている必要がある。例えばデータベースはどのようなレコードから構成されるか、レコードにはどのような属性(attribute)があって、それはどんなタイプのデータがどんな値をとり得るかといったことである。このようなデータ定義に基づくデータベースの論理的な構造をスキーマ(schema)という。分子生物学の分野では、データを単純なテキストファイルの形に編成したフラットファイル(flat file)データベースが数多く存在するが、そこでのデータ定義はフォーマット(format)と呼ばれ、これも広い意味のスキーマに相当する。
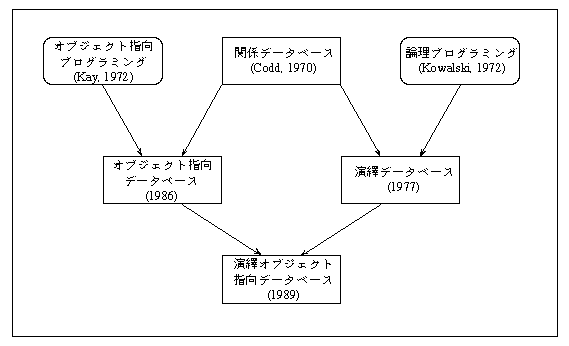
データベースを構築するときに、実世界のデータを計算機のデータとして表現し操作する必要がある。その基礎となるのがデータモデル(data model)と呼ばれる概念体系および操作体系である。代表的なデータモデルとして、階層モデル、網(ネットワーク)モデル、関係(リレーショナル)モデルといったものがあるが、とくに対象の表現に関係(relation)だけを用いる関係モデル、それに基づく関係データベース(relational database)が現在最もよく使われている。関係モデルは1970年にコッド(Edgar F. Codd)により提唱された。ここでは関係データベースのほか、演繹データベース、オブジェクト指向データベースなどのデータベース技術の進歩(上図)を分子生物学にどのように生かしていくことができるのかを考えてみよう。