ゲノムの情報科学

[ゲノム情報]
ゲノム計画の目標はバクテリアから高等生物まで、各種生物がもつゲノムのDNA文字配列(塩基配列)をすべて決定することです。しかしながら、文字列が決まればそれで終わりではありません。書かれている生物的な意味を理解できなければ、文字列を本当に読み取ったことにはならないからです。1995年にウイルス以外の生物として初めてゲノムの全塩基配列が決定されたヘモフィルスに続き、パン酵母、らん藻、枯草菌など、続々と異なる生物ゲノムの全塩基配列が決定されるようになりました。ところが、そこから見つかった何千もの遺伝子の 1/3 から 2/3 はどんな働きをしているのかよく分からないままになっています(「機能予測」の項参照)。生物科学と情報科学の融合の中から新しい生物情報処理技術を開発し、ゲノム塩基配列の生物的意味解釈を可能にして、生命現象の解明に挑んでいるのが「ゲノム情報」の学問です。

[ゲノムネット]
基礎生物学から医学・薬学・農学まで広く生物科学は、ゲノム計画の波及効果により急速な情報化が進んでいます。情報化には2つの意味があり、1つは情報処理技術が実験技術と同じように生物科学の研究を行う上で不可欠の要素になってきたこと、もう1つはゲノム計画がもたらす大量データの出現によりデータベースの重要性が高まったことです(「データベース」の項参照)。文部省のヒトゲノムプログラムでは、大量データの出現による生物科学の急激な展開に対応するためには、情報インフラストラクチャーの整備が不可欠であるとの認識から、1991年にコンピュータネットワーク「ゲノムネット」を設立しました。ゲノムネットは文部省プロジェクトで開発されたものも含め、世界中に存在する生物学・医学関連の多様なデータベースや解析ツールを、各研究者のデスクトップで統合して利用できる環境を提供しています。ゲノムネットのホームページには世界70カ国から毎日何万件ものアクセスがあります。
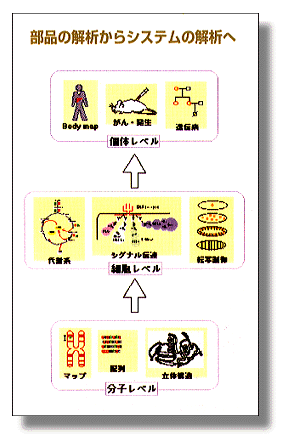
[生命の設計図]
ゲノム計画は生命の設計図を読み取る計画だと言う人がいます。しかし、これは厳密には正しくありません。ゲノム計画とは生命の部品のカタログ、つまり生物がもつすべての遺伝子とその産物である分子(タンパク質とRNA)のカタログ、を調べ上げる計画なのです。当然ながら、個々の部品の働きが分かっても、生命の全体的なシステムとしての働きが分かるわけではありません。部品がどのようにつながっているのか、すなわち部品間の結線図が解明されなければ、本当の意味で生命の設計図を読みとったことにはならないのです。重点領域研究「ゲノムサイエンス」では、分子同士あるいは遺伝子同士の相互作用を単位としてデータや知識を集積し、代謝、発生、がん化を始めとした生命現象の様々な側面を、分子反応パスウェイあるいは遺伝子発現制御のパスウェイとして体系化する研究を行っています。
[データベース]
ゲノム研究では個々の生物種に関するデータベースの他に、文献、遺伝病、遺伝子地図、塩基配列、アミノ酸配列を始め、様々なタイプのデータベースが必要です。これらのデータベースは世界各地で作成され、しかも日々更新されていること、異なるデータベースのデータ間に生物的な関連が内在すること、テキスト、イメージ、グラフィックスなどのメディアで表現されていることから、インターネット、ハイパーリンク、マルチメディアといったキーワードをもつ WWW(ワールドワイドウェブ)の環境にうってつけです。実際、WWW の普及によりコンピュータが苦手だった生物学者にもデータベースが非常に身近なものになりました。また、ゲノムネットなど多くの WWW サービスは誰でも自由に利用することができますので、将来を担う子供たちの学校教育や一般家庭での教養のためにも活用していただきたいと思います。
[機能予測]
物理学や化学における計算と、生物学における計算を比べてみると、前者はニュートン方程式を解くといった原理的な計算をして予測をすることができるのに、後者にはまだそれほどの予測能力がありません。これは生命の基礎データであるゲノムをようやく解読できるようになった生物学の現状を反映しています。大量のデータの中からまず経験的な法則が解明され、そしてしだいに生命の基本原理が体系化されていくことでしょう。現在、新しい遺伝子の機能を予測する方法として、ホモロジーサーチが一般的です。これは、配列が類似であれば生物的な働きも類似なので、過去に似た配列の遺伝子があるかデータベースを検索する方法です。ただし、これで予測できる遺伝子の数は全ゲノムの半分前後であること、つまり検索で全くヒットしない場合や、ヒットしてもその相手の機能が分かっていない場合が多いことが、ホモロジーサーチの限界です。

