
|

|
|
|
|
階層型ニューラルネットは古くはパーセプトロン(perceptron)と呼ばれ、学習のモデルとして研究されてきた。応用面でも音声認識や手書き文字認識など、さまざまなパターン認識に利用されている。階層型ニューラルネットは入力データを受けると何か答えを出力する。これをたくさんのデータで何度も繰り返し、答えが合っていたか間違っていたかを教えてやることにより、ニューラルネットはだんだん賢くなっていつも正しい答えを出すようになる。これを教師付き学習(supervised learning)というが、ニューラルネットが学習した結果はネットワークのユニット間の結合の重みとして蓄積されるのである。
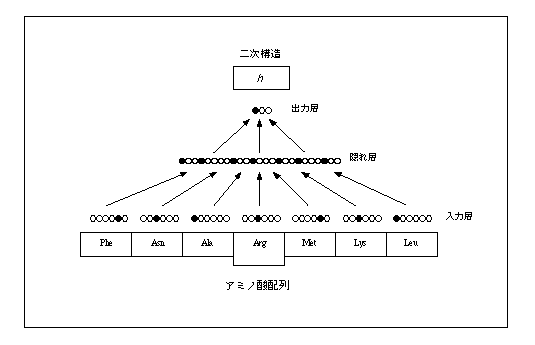
タンパク質二次構造予測にニューラルネットを最初に適用したのは Qian-Sejnowski 法である。図に概念図を示したが、基本的に GOR 法と同じように何残基かのセグメントをとり、中央の残基がどの二次構造にあるか3状態予測を行う。まず立体構造既知のタンパク質の配列データでトレーニングデータセット(training data set)を作り、教師付き学習にはバックプロパゲーション(back propagation)法と呼ばれる学習アルゴリズムが使われている。図の入力層と出力層以外の層を隠れ層(hidden layer)といい、バックプロパゲーション法は隠れ層の学習を可能とするアルゴリズムとして提案された。ネットワークの出力値と教師が教える真の値との差が誤差であるが、この誤差が最小になるようまず出力層への重みの最適化を行う。これをもとに1つ前の隠れ層の誤差を最小とするよう重みの最適化を行う。隠れ層の数だけこれを繰り返し、入力層まで誤差を逆伝播(バックプロパゲーション)させるのでこの名前がある。 バックプロパゲーション法では、エネルギー関数の最急降下法による最小化の考えにより、ユニット間の結合の重みを逐次的に変化させていく。ここでは一番簡単な出力ユニットの学習則を求めてみよう。いま、ユニット iからユニットjへの重みをWijとすると、学習則はそれぞれの重みの増分ΔWijとして表現され、これはエネルギー E をΔWijで偏微分した傾きに比例する。
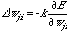
ここで
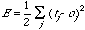
は各出力ユニットの出力値ojと目標値tjとの誤差の自乗和として定義される。いま、OJは出力ユニットへの入力値iiの重みつき和に対し活性化関数を通した値
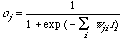
であるとすると、上記の偏微分を実行することにより、出力ユニットへの重みの学習則を計算できる。